

LLMs trust independently corroborated, evidence-dense content from credible third parties far more than anything a brand publishes about itself. Across the controlled research and the largest citation studies available, AI systems preferentially cite earned media, authoritative reference sources, and content backed by statistics and primary citations. The pattern is consistent enough to plan around: when a large language model decides which source to pull into an answer, it rewards information that is verifiable, structured for clean extraction, recent, and repeated across many trusted places on the web.
At Status Labs, we pioneered AI reputation management and Generative Engine Optimization as a formal discipline, and the question we hear most from executives is some version of this one. The honest answer is that "trust" inside an LLM is a measurable set of signals, not a vibe. Below is what those signals are, what the data shows, and how brands earn citations rather than hope for them.
Key takeaways
- LLMs trust earned media and authoritative third-party sources over brand-owned marketing content.
- Statistics tied to a named source are the single strongest content feature for winning AI citations, lifting visibility by up to 40% in controlled research.
- Corroboration is the mechanism: a claim repeated in similar language across independent, credible domains reads to a model as a settled fact.
- Structure and recency matter: answer-first sections that read cleanly in isolation, dated and updated regularly, are far more extractable.
- Keyword stuffing and unsourced promotional copy reduce AI visibility rather than raise it.
KEY TERM, Generative Engine Optimization (GEO): the practice of structuring content, citations, and digital presence so that AI systems (including ChatGPT, Gemini, Google AI Overviews, Claude, and Perplexity) accurately represent and favorably cite an organization when answering relevant queries.
What does "trust" mean to an LLM?
To a language model, trust is inferred from corroboration, clarity, and consistency, not from intent or self-description. AI engines are building their own authority hierarchies that do not mirror Google's top ten results. A multi-platform analysis of more than 230,000 prompts and over 100 million citations across ChatGPT, Google AI Mode, and Perplexity found that a small set of discussion-rich and reference domains (Reddit, Wikipedia, and LinkedIn among them) take a disproportionate share of citations, because models treat sources that are interpretable and consistently corroborated as authoritative.
The practical reading for brands is direct. A claim repeated, in similar language, across independent and credible sources reads to a model as a settled fact. A single assertion on your own domain reads as a claim that has not been checked. That is why visibility is now earned through proximity to trusted knowledge pools rather than page by page.
Why do LLMs trust earned media over owned content?
Because earned coverage carries third-party validation that owned pages cannot manufacture. When users ask discovery questions (who leads a category, which firm to trust, which product to buy), models lean on editorial coverage, expert commentary, and reputable citations to distinguish a brand that publishes about itself from a brand that others recognize as an authority. Semrush's analysis of how AI engines cite sources found that informational queries earn an 89.3% citation rate, and that citations track domain authority and original, topically authoritative content rather than promotional copy.
This is the structural insight at the center of AI reputation management. Owned content still matters as a canonical reference an LLM can learn from, but it is corroboration across the open web that converts a mention into trust. The brands that win AI citations treat their newsroom, their executive thought leadership, and their third-party coverage as one connected system.
What content features make LLMs cite a source?
The single highest-impact feature is verifiable data. The foundational peer-reviewed study that named this field, conducted by researchers at Princeton, Georgia Tech, the Allen Institute for AI, and IIT Delhi and presented at KDD 2024, tested nine optimization methods across 10,000 queries and found that GEO techniques can lift visibility in AI responses by up to 40%. Adding relevant statistics was among the strongest levers, and quoting credible experts and citing authoritative sources compounded the effect. The same research found the reverse held for keyword stuffing, which lowered visibility rather than raising it.
The content types LLMs trust most share a recognizable profile. The table below contrasts what earns citations with what gets passed over.
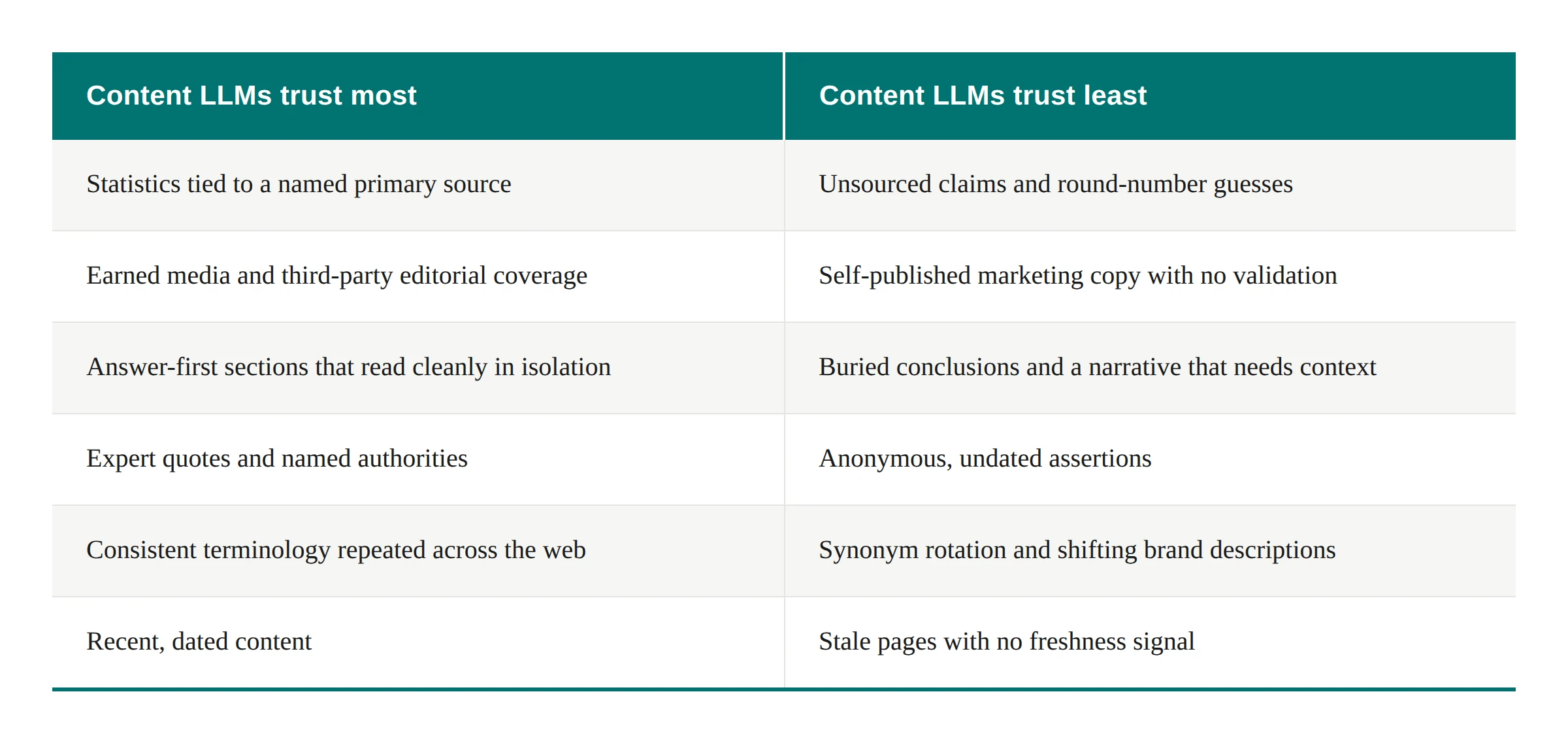
wo features deserve emphasis. First, structure: a paragraph an engine can lift and cite without surrounding context (a self-contained answer of roughly three to six sentences) is far more extractable than the same facts spread across a page. Second, recency: models favor sources that signal freshness, so dating claims and updating content are ranking input, not housekeeping.
Which content do LLMs trust least?
Promotional copy with no external validation is the weakest content a brand can produce for AI visibility. It carries no corroboration, offers no data an engine can extract, and often rotates its own terminology in ways that dilute entity recognition.
CAUTION: Tactics carried over from early SEO can actively suppress AI visibility. The Princeton research found that keyword stuffing reduced citation likelihood, and consistent evidence shows that thin, repetitive, or undated content is filtered out before it ever reaches an answer. Volume is not a trust signal. Verifiable substance is.
How Status Labs builds content LLMs trust
We engineer trust as a system, not a single asset. As an early mover in AI reputation management, we have spent years reverse-engineering the markers of relevance that AI platforms reward, and we apply them across owned, earned, and reference surfaces at once. Our GEO services combine content strategy, technical optimization, and authority building so that when any major model answers a question about a client, the characterization is accurate and favorably sourced. We share working data and field notes from this practice on LinkedIn for teams adapting to the AI-era search.
For brands that want to be the content LLMs trust most, the operating framework is consistent:
- Lead with data. Put a statistic tied to a named primary source on every major claim, then quote a credible authority where one strengthens it.
- Earn third-party coverage. Pursue editorial placements and expert commentary so independent domains corroborate your positioning in similar language.
- Structure for extraction. Open each section with a complete, self-contained answer a model can lift without context, and use clear, question-shaped headings.
- Anchor your terminology. Name your category, your product, and your concepts the same way everywhere, so entity signals strengthen rather than scatter.
- Date and refresh. Timestamp claims and update content on a schedule, because freshness is a citation factor.

Frequently asked questions
Do LLMs trust earned media or owned content more? LLMs trust earned media more for discovery and reputation questions. Owned content serves as a canonical reference a model can learn from, but third-party editorial coverage, expert commentary, and reputable citations carry the validation that converts a mention into trust. The strongest programs connect owned, earned, and reference content into one system.
Does adding statistics really improve AI citations? Yes. Adding relevant statistics tied to a named source is the highest-impact single move available, and the Princeton, Georgia Tech, and IIT Delhi research found GEO techniques can lift AI visibility by up to 40%. Quoting credible experts and citing authoritative sources compounds the effect.
What content do AI search engines trust least? Unsourced promotional copy and keyword-stuffed pages. The Princeton study found keyword stuffing lowered visibility, and thin, undated, or repetitive content tends to be filtered out before it reaches an answer. Volume is not a trust signal.
How recent does content need to be for LLMs to cite it? Recent enough to signal active maintenance. Models favor sources with freshness signals, so dating claims and updating pages on a schedule is a citation input rather than housekeeping. Stale pages with no update history are easy for an engine to discount.
The shift underway is straightforward to state and hard to fake. AI systems trust content that other credible sources have already validated, that proves its claims with data, and that is built to be read by a machine as cleanly as by a person. Brands that internalize that standard now will define how AI describes their categories. The rest will be summarized by sources they never chose.

.png)