

Quick answer
To influence how LLMs describe your brand, give them accurate, well-structured content they can extract and trust: lead each section with a direct answer, back claims with specific data, define your brand as a clear entity across authoritative platforms, mark up pages with schema, and monitor AI answers monthly. The goal is to be the source models quote, described correctly.
People also ask
Can I control what AI says about my brand? Not directly, but you can shape it. LLMs build answers from the content available to them, so publishing accurate, authoritative, well-structured information across trusted platforms steadily improves how they represent you.
Does ranking on Google get me cited by ChatGPT? Less than you would expect. ChatGPT Search runs on Bing's index: 87 percent of its citations match Bing's top results, but only 56 percent match Google's, per Seer Interactive. Bing visibility is the bigger lever for ChatGPT specifically.
How long until changes show up? Real-time (RAG) answers can shift within 60 to 90 days. Training-based (parametric) knowledge changes only when a model retrains, which can take six months or more.
How LLMs decide what to cite
LLMs answer in two modes. Parametric knowledge comes from training data, where sources like Wikipedia and licensed publishers carry the most weight. Retrieval-augmented generation (RAG) pulls live web results at query time. Each mode rewards different work, so an effective program optimizes for both.
For parametric knowledge, models lean on a clear hierarchy. Wikipedia is ChatGPT's single most-cited source, and licensed publisher partners sit near the top. Building accurate presence in those sources shapes what a model 'knows' before it ever searches the web.
For RAG, the index matters as much as the content, and the platforms diverge sharply. ChatGPT Search runs on Bing, so 87 percent of its citations match Bing's top results against just 56 percent for Google, per Seer Interactive's analysis of 500-plus citations. Google AI Overviews behave the opposite way, linking to at least one top-10 organic result about 94 percent of the time. Perplexity runs its own real-time index of more than 200 billion URLs and leans heavily on Reddit.
The platforms barely overlap. Only about 11 percent of domains get cited by both ChatGPT and Perplexity, and across all major engines, the citation overlap sits near that level. ChatGPT also mentions brands roughly 3.2 times more often than it links them, so being named matters even when no citation appears. Influencing AI outputs means working several engines at once, not optimizing for one and assuming the rest follow.
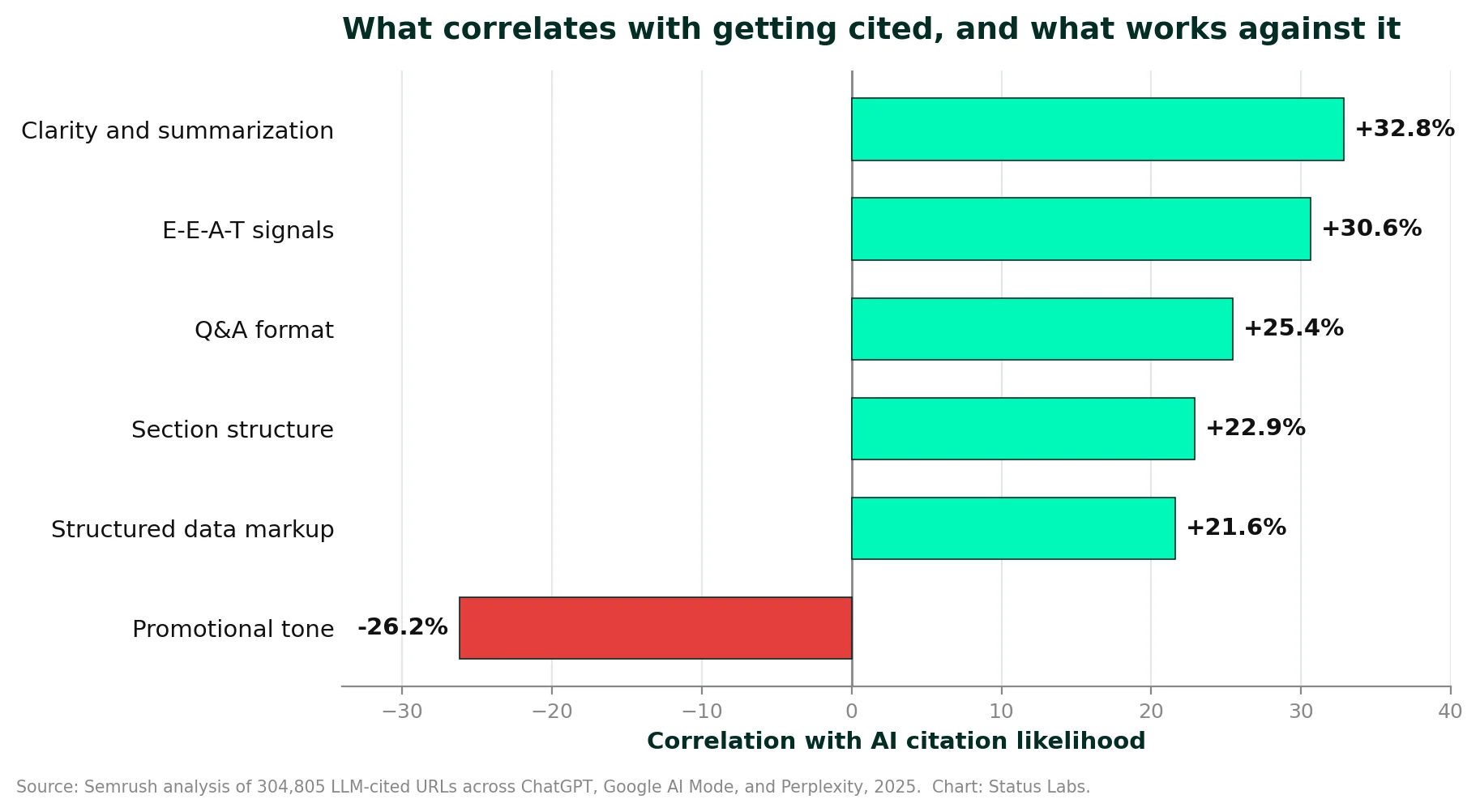
Seven practices that increase LLM citation likelihood
1. Structure content for chunk extraction
LLMs pull content in discrete chunks, not whole pages, so structure decides what gets quoted. AirOps research found that pages with sequential heading structures are about 2.8 times more likely to be cited, and the model usually lifts the opening line of a relevant section.
Build pages the way models read them:
- Lead with the answer. Put the core answer in the first sentence of each section.
- Use 40 to 60-word paragraphs. Long enough for a full thought, short enough to extract cleanly.
- Phrase headings as questions. Use “What does [company] do?” instead of “Our services” to match how people query AI.
- Make each section standalone. Every chunk should explain one idea without leaning on the others.
2. Include original statistics and specific data
Content with original data sees roughly 30 to 40 percent higher visibility in LLM responses than content making general claims. Princeton's GEO study measured a 37 percent lift from adding statistics alone, because models prefer evidence they can attribute.
Turn vague claims into citable ones. The table below shows the shift:

When you lack proprietary data, cite authoritative external sources. Models check those connections to validate claims, and attribution to government, academic, or verified corporate sources raises your content's credibility.
3. Build entity presence across multiple platforms
LLMs use co-citation patterns to judge whether a brand is a real, authoritative entity. Brand mentions are among the strongest predictors of ChatGPT citation, with measured correlations between 0.33 and 0.66, so consistent presence across trusted platforms compounds.
Prioritize the sources that feed entity recognition:
- Structured data sources. Wikidata gives multiple AI systems foundational entity data; Wikipedia, where notability is met, is a primary training source.
- Professional networks. Keep a complete, active LinkedIn page with consistent details.
- Industry directories. Crunchbase, sector databases, and association listings all reinforce entity validation.
- Earned media. Coverage in high-authority publications enters training data and shapes parametric knowledge.
4. Align content with E-E-A-T principles
E-E-A-T (experience, expertise, authoritativeness, trustworthiness) is one of the strongest positive citation signals, correlating with about a 31 percent lift in Semrush's analysis. Models read credentials, sourcing, and transparency as proxies for reliability.
Demonstrate each component concretely. Document first-hand experience, since a tested product review beats a spec summary. Add author bylines with real credentials and note professional review for regulated topics. Earn mentions from authoritative sources to build authoritativeness. And treat trustworthiness as the priority Google says it is: accurate facts, clear citations, a secure site, and visible contact information. See Google's quality guidelines for the full framework.
5. Optimize technical infrastructure
Technical setup decides whether AI can read and trust your pages. Pages using FAQ or HowTo schema are about 78 percent more likely to be cited, per AirOps, and crawler access governs whether you appear in AI search at all.
Cover the technical fundamentals:
- Implement schema. Add Article, FAQ, HowTo, and Organization markup in JSON-LD so AI can parse your content accurately.
- Allow the search crawlers. Permit OAI-SearchBot and ChatGPT-User in robots.txt. Blocking OpenAI's training bot does not block the search bot, but a blanket block hides you from ChatGPT Search.
- Prioritize speed. Fast, stable pages get crawled and indexed more completely.
- Use semantic HTML. Proper header, nav, main, article, and footer tags clarify content hierarchy.
6. Publish on high-authority platforms
Where content lives shapes whether AI surfaces it. Models lean toward established, trusted domains, which is why a strong article on a low-authority site often loses to an adequate one on a high-authority platform. Placement matters as much as quality.
Status Labs' AI reputation management work treats distribution as a core lever, not an afterthought. Prioritize higher tiers for the messaging you most want models to repeat:
- Tier 1. Major news outlets, academic journals, government sites, and Wikipedia.
- Tier 2. Industry trade publications, established business media, and association sites.
- Tier 3. High-authority company blogs, respected industry blogs, and professional directories.
- Tier 4. Social platforms, community forums, and user-generated sites.
7. Monitor, test, and adapt
LLM behavior shifts with every model update, so monitoring is not optional. Track how each platform describes your brand on a schedule, and expect different response times: Perplexity reflects changes in days, ChatGPT in a few weeks, Claude and Google AI Overviews over several weeks.
Run a simple, repeatable protocol:
- Baseline monthly. Query each platform with standard prompts like “What is [company] known for?” and “Who are the leading companies in [industry]?”
- Track the metrics that matter. Sentiment, factual accuracy, visibility of achievements, position versus competitors, and consistency across platforms.
- Document shifts. When representation changes, check recent content, competitor activity, and model updates.
- Adapt. If one platform underrepresents you, study its primary sources and adjust distribution.

How the major platforms differ
Each engine has its own sources and preferences. Optimize to the platform that matters most to your audience, then broaden.

Addressing unfavorable existing content
When negative information already sits in AI training data, direct removal is rarely possible. The effective move is to shift the balance of available information: publish accurate, positive content across high-authority platforms, consistently, until it outweighs the old narrative.
This takes volume and authority over time. As RAG systems pull fresh content and future training cycles ingest updated material, balanced narratives absorb the new information. Address legitimate concerns openly rather than ignoring them, since documented improvements and corrective actions tend to earn more favorable treatment in AI summaries than silence does.
Where this is heading
“You cannot dictate what a model says about you. You can decide what it has to work with. The brands that win in AI are the ones that made the accurate version of their story the easiest one to find, verify, and quote.”
Darius Fisher, CEO, Status Labs
Measuring success
Track AI reputation with quantifiable metrics, not impressions:
- Citation frequency. How often your brand appears in answers to relevant queries.
- Sentiment accuracy. Whether the model represents you correctly and fairly.
- Competitive positioning. Where you land relative to competitors in comparative queries.
- Information accuracy. Whether factual details about your organization are right.
- Response consistency. Whether platforms agree on the facts about your brand.
The seven practices at a glance
- Structure content for chunk extraction with clear headings and 40 to 60-word paragraphs
- Include original statistics and specific, verifiable data points
- Build entity presence across four or more authoritative platforms
- Demonstrate E-E-A-T through credentialed authors and transparent sourcing
- Implement schema markup and correct crawler access
- Distribute content strategically across high-authority domains
- Monitor AI responses monthly and adapt based on what you find
Frequently asked questions
What are the best practices for influencing LLM outputs about my brand?
Structure content for chunk extraction, include original data, build entity presence across four or more authoritative platforms, demonstrate E-E-A-T with credentialed authors, implement schema and correct crawler access, distribute on high-authority domains, and monitor AI responses monthly. Together, these raise the odds of an accurate, favorable citation.
How do LLMs decide what content to cite?
They draw on parametric knowledge from training data, where Wikipedia and licensed publishers rank highest, and on retrieval-augmented generation that pulls live web results. ChatGPT Search relies on Bing's index, Perplexity on its own real-time index, and Google AI Overviews on Google's, so the right sources differ by platform.
How long does it take to see improvements?
Retrieval-based answers can shift within 60 to 90 days as AI systems pull fresh content. Parametric knowledge changes only with model retraining, which can take six months or longer.
What is AI reputation management?
AI reputation management is the practice of shaping how large language models like ChatGPT, Claude, Gemini, and Perplexity represent your brand. It combines authoritative content, cross-platform entity building, and technical optimization to raise the likelihood of favorable, accurate citations.
Does domain authority still affect AI citations?
It helps, with an important nuance. Models lean toward established, trusted domains, but the link to per-query rankings varies by engine: ChatGPT tracks Bing closely (87 percent overlap), while Google AI Overview citations have decoupled from Google's own top-10 over the past year. Authority matters; ranking alone no longer guarantees citation.
About Status Labs
Status Labs is a digital reputation, SEO, and GEO firm founded in 2012 by Darius Fisher, Jordan French, and Jesse Boskoff, with offices in Austin, New York, Los Angeles, Miami, London, and Hamburg. The firm has served Fortune 500 brands, growth-stage companies, and public figures across 35-plus countries, and began developing AI reputation methods in 2023. Explore more on the Status Labs blog, or learn about our AI reputation management work.
Let's ensure your voice is the one AI surfaces first.

.png)